【数据仓库架构】数据建模:星型模式
数据建模是现代数据工作流中的一个关键步骤,其目的是将原始数据组织成方便、高效的形式。如果一个可用的数据集易于访问,数据分析师和科学家将发现他们的工作更加容易。更快的分析和预测将导致更快的商业决策洞察力。
建模的第一步通常是规范化数据,这是一个组织过程,通过减少不一致的依赖性和冗余来提高数据库的灵活性。如果你不熟悉的话,我建议你读一下这个和/或看一些视频!规范化数据库的问题是,任何真正有意思的数据洞察都需要许多连接,随着数据库大小的增加,这些连接会大大降低查询的速度。例如,查看下面的模式,大多数表都不是直接相关的。这意味着要连接订单和位置等两个表中的信息,我们至少需要4个连接(Orders -> Employment -> Person -> Phone_Number -> Location是到达那里的一种方式)

https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-relational-modeling.html
如果在4部分连接之后我们需要更多表的数据呢?那将是疯狂。更不用说,如果只编写查询而不出现任何错误,那将是一个绝对头疼的问题。
此外,实际数据库中的表可能比上面示例中显示的表多得多。正如您可以想象的那样,随着模式的增长,甚至越来越难以理解表之间的关系。
星型模式
解决这个问题的一个方法是执行数据建模的非规范化步骤,以创建一个更简单、易于理解的为ceratin查询优化的模式。创建星型模式的过程包括将完整的模式提取为特定分析过程的相关特性。星型模式的总体结构如下:
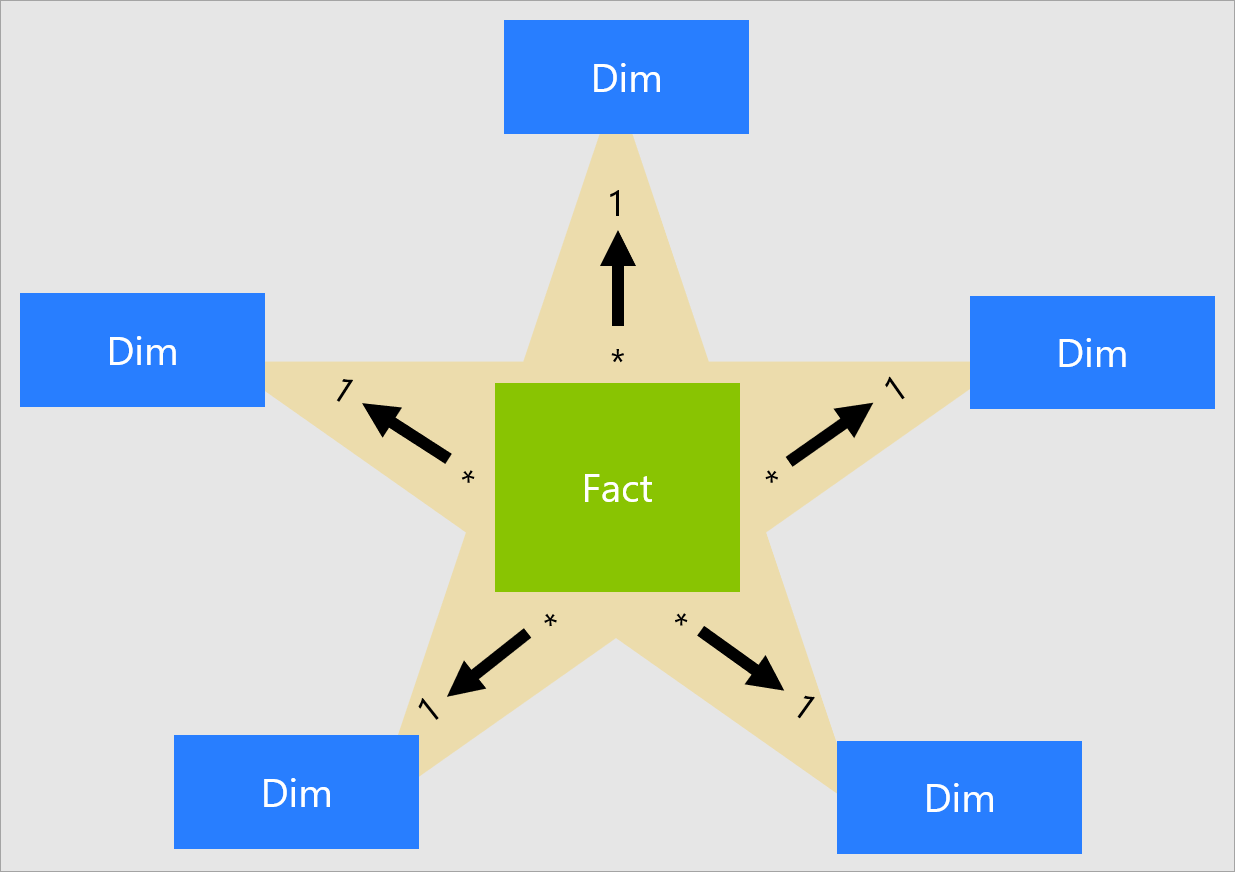
https://docs.microsoft.com/en-us/power-bi/guidance/star-schema
星型模式由两种类型的表组成:
- 事实:业务流程的度量。这些通常是数字和加法(例如发票金额或发票数量)或数量。事实表还包含指向相关维度表的键。在星型模式的中心只有一个事实表。
- 维度:地点、时间、内容等(如日期/时间、地点、销售商品)。它们通常包含定性信息。数据模式中有多个维度表,它们都与事实表相关。
优势
- 一个简化的模式意味着我们不必每次想要从数据库中获得一些信息时都编写冗长的查询。
- 我们对阅读进行了优化。现在我们可以编写更少的连接,结果将更快地返回。
- 而且,它将业务逻辑用于报告。我们不必向涉众解释所有用于创建模式的疯狂连接,只是可能。
缺点
- 对数据进行非规范化意味着数据异常可能是一次性插入或更新引起的。在实践中,星型模式是通过“涓流喂养”(trickle feeds)或批处理来实现的,以弥补这个问题。
- 我们的分析灵活性有限。星型模式通常是为特定目的而设计的。由于星型模式中的特性比完整数据库中的少,因此我们仅限于此星型模式包含的内容。
例子
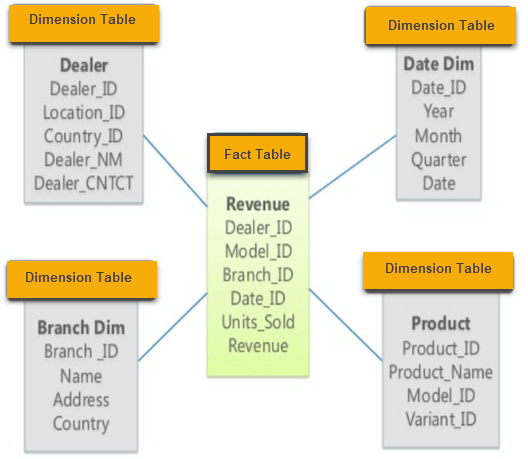
https://www.guru99.com/star-snowflake-data-warehousing.html
让我们考虑一个商店的销售数据库。我们在模式的中心有一个事实表Revenue和四维表。
事实表由复合主键组成,复合主键是维度表主键的组合。事实表非主键Units_Sold和Revenu是我们感兴趣的事实,Product_Name和Name (分支名称)等维度使我们能够了解有关销售商品的更多信息。
例如,以下查询将允许我们计算2010年按产品列出的总收入:
SELECT
p.Product_Name AS product,
SUM(r.Revenue) AS total_revenue
FROM
Revenue r
JOIN
Product p ON (r.Model_ID = p.Model_ID)
JOIN
DateDim d ON (r.Date_ID = d.Date_ID)
WHERE
d.Year = 2010
GROUP BY
p.Product_ID
星型模式被广泛使用,对业务应用程序非常有用。它有助于我们加快可能经常运行的查询,并清理可能非常混乱的查询等。
还有其他模式,如雪花模式和星系模式,它们是恒星模式的简单扩展。如果你喜欢星型模式,我建议你也检查其他的!
原文:https://medium.com/@marcosanchezayala/data-modeling-the-star-schema-c37e7652e206
本文:http://jiagoushi.pro/node/1025
讨论:请加入知识星球或者微信圈子【首席架构师智库】
- 360 次浏览