Rust语言
- 165 次浏览
【Rust开发】Java 比优化后的 Rust 程序更快
QQ群
视频号

微信

微信公众号

知识星球
你好。 起初,我是一名 Rust 程序员,并为它编写了一些项目和一个框架,在听说动态编译技术后,JVM 对我很有吸引力,我在 rust 中编写了一个带有许多优化标志的程序,以便编译器获得最佳性能 ,并在java中编写实例。
经过热身时间后,我看到了 JVM 的惊人性能,它是一头野兽,可以在性能上击败 Rust,
Rust result: 10,648 _ 6,678 _ 8,274
Java result: 8,661 _ 9,608 _ 6,302
12次基准的平均值:
Rust: 9,948
Java: 8,693
Java 代码:
public static void main(String[] args) {
for (int q = 0; q < 1001; q++) {
long tInit = System.nanoTime();
ArrayList<CClass> arr = new ArrayList<CClass>(100);
for (int i = 0; i < 100 ; i++) {
arr.add(new CClass("fname", "lname", i % 30));
}
for (int i = 0; i < 100 ; i++) {
CClass cls = arr.get(i);
cls.validation();
}
if (q > 997) {
System.out.println(System.nanoTime() - tInit);
}
}
}
Rust Code :
fn main() {
for _ in 0..3 {
let now = std::time::Instant::now();
// ===============================================
let mut v = Vec::with_capacity(100);
for i in 0..100 {
v.push(Class::new("fname", "fname", i % 30));
}
for i in 0..100 {
let cls = v.get(i).unwrap();
cls.validation();
}
// ===============================================
let now2 = std::time::Instant::now();
println!("==> {}", now2.duration_since(now).as_nanos());
}
}
我使用一些 rust 编译器标志来最大化性能:
[build] rustflags=[“-C”, “target-cpu=native”] [profile.dev] lto = true opt-level = 3
最后,我越来越喜欢 JVM,java/Scala
伟大的语言,庞大的生态系统和惊人的性能,
阿里巴巴、Linkedin、Twitter、亚马逊使用 80% 的后端工作在 JVM 上,
这不仅仅是为了 JVM 的独立性或生产力
它具有惊人的性能和惊人的稳定性
精彩评论1
Java(和 JVM)一点也不慢。 不知道是什么给了你这样的印象。
例如,现代 JavaScript 引擎和现代 JVM 一样快。
当您只对非常简单的循环代码进行计时时尤其如此,这些代码大多会生成相同的程序集。 而且,正如一条评论所说,您可以通过迭代器优化 Rust 的边界检查,这应该会使其更快。
抱怨 Java 和 JavaScript 等不是因为它们很慢,而是因为 GC(垃圾收集)而_偶尔_慢。 并且需要占用大量运行时间(因此需要大量 RAM)。
在您的示例中,您既不会使用大量内存,也不会导致任何 GC。 因此,我希望 Java 速度与 Rust 速度相似,因为没有理由不应该这样。
评论2
当您比较不同的分配器时有点不公平。 Java 预先分配内存并为每个分配请求移动一个指针,rust 实际上向系统分配器请求内存。 这是托管 Vs 本机语言的一个已知位,它与 c# 和 c++ 或其他任何语言相同。 如果将分配移到时区之外会发生什么?
评论3
jvm 通过分析程序和找出热路径来调整优化。 一个公平的比较将根据性能配置文件对 rust 程序进行分析和重新优化
评论4
Java 性能的主要问题是它的 GC,它会增加延迟,最重要的是会使请求处理的延迟变得难以预测。 内存管理的可预测性是没有 GC 的语言的优势之一。 当然,我过于简单化了,因为性能是一个相当复杂的领域
评论5
是的,谢谢,我们可以运行一个 10K rps 的 java 服务器,内存使用率很高
但实际上与 Rust Instance 的区别是,Java 使用 2GB,Rust 使用 10MB。
是的 GC 是数据库软件的问题,但不是没有 ZGC 的 Web 服务器,
但是云托管服务器2GB的钱不算什么
但是时间很昂贵,而且经过良好测试的库更重要,
例如 Akka-grpc 在多核服务器上比 Rust-Tonic 更快
因为库经过了很好的测试,但在 Rust 社区中不存在某些东西,例如我们社区中有 Sqlx (Async orm) 和 Diesel(Sync orm) 是关于哪个更好的战争!!。
不存在直接的解决方案 这个问题也存在于 cassandra 驱动程序中,并且文档是旧的并且与新版本不同。
这对我来说很痛苦。
但是在 jvm 中几乎所有东西都直接存在
评论6
这是正确的。 如果您的环境可以使用 2GB 的内存并且 Java 的 GC 对您来说不是问题,那么您应该使用适合您的目的的最佳技术。
对于某些人来说,例如在嵌入式环境中,您没有使用 2GB 的奢侈,并且您无法维持 GC 暂停,那么您可能会选择 Rust。
原文:https://towardsdev.com/java-is-faster-than-optimize-rust-program-bd0d17…
本文:
- 79 次浏览
【Rust开发】Rust 一年后

好吧,距离我上次写已经有几个月了,但是时间过得真快🕊️
所以这是我在 Rust 进行微服务 Web 开发一年后的小日记,主要是一些想法的集合。
学习曲线
我有时听说使用 Rust 需要 1 个月才能获得生产力。
好吧,我不是计算机科学专业的毕业生(实际上我的专业更侧重于项目管理),但我仍然在这个领域工作了 13 年以上,对此我不太同意。 也许它对以前的系统程序员来说更容易,或者也许有些人比其他人学得更快。
仅作为一个比较:据我所知,JavaScript 花了我 1 个月的时间来适应,而在 6 个月内就可以高效地完成任何编码任务。
Rust 是……不同的。
而且我学习它的背景也不同:我以前也是唯一的 Rust 知识可以追溯到 2019 年初,当时我终于彻底阅读了 Rust 书。我非常简单地尝试设置对 websocket 的基本客户端请求。说我理解了那里的所有概念,或者说我在 2020 年记得它们,那将是一个公然的谎言。刚签下新合同,我应该接受 Rust 的培训。事实证明,就像经常发生的那样,我必须自己学习,同时仍然必须在截止日期内交付功能。谢天谢地,合理的那些给了我足够的时间来改进,但还不足以正确地阅读文档、观看学习资源、进行实验等等。大多数情况下,这必须在我的空闲时间完成,我做了很多。老实说,这是令人筋疲力尽的一年。
我想说的是,在第一个月之后,我能够编写 Rust 代码,而无需每隔 2 分钟左右就对编译器的错误感到惊讶。到那时我已经习惯了它们中的大多数,并且已经习惯了基础知识。熟悉编译器的错误是必要的:这意味着你了解编译器想要你做什么。
不知何故,漫长而广泛的特征仍然会让我目瞪口呆,例如这个:
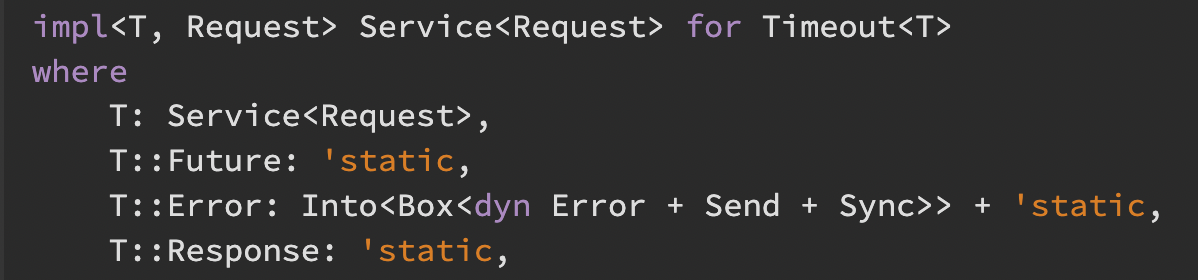
那么这是什么?您可以将其称为另一种语言的“界面”。
它在这里描述了一个中间件,它将对其请求强制超时。
它接受一个通用请求,并将在将来的某个时间(也就是说,异步)返回一个通用响应或一个通用错误。
首先,这里有趣的是,只要此代码在范围内,此 Timeout 将自动为您的库、标准库或任何在 Rust 中创建或将要创建的库中的任何类型实现。
注意到这个淘气的 T::Error 了吗?它需要任何可以转换为指向动态大小错误的指针(其大小在编译时未知,基本上允许您自由传递任何类型的错误)装箱在堆上的某处(哦,这个指针也是顺便说一句,保证是非空的,但这是另一个话题)。这个“错误”对于线程之间的发送和同步(或共享,如果您愿意)也是安全的(以便运行时可以在多个线程上正确调度任务,如果认为合适的话)。两种响应变体都必须在内存中存在足够长的时间才能完成异步调用,这就是“静态”在这种情况下所表示的。
Rust 语言确实过于表达。
但是一旦你开始理解它,它就是美丽的。
3 个月后,我终于熟悉了它们,编写自定义实现有时很乏味,但最终还是完成了。
我也借此机会感谢整个 Rust 社区,尤其是 tokio 和 tonic 的贡献者和维护者。他们总是不遗余力地提供提示并善意地为我指明正确的方向。不管我的问题多么愚蠢,有时。
作为我自己故事的旁注,如果我可以说的话,Rust 有“很多方面”。其中之一是元编程,或称为宏。它基本上是允许您生成代码的代码。我很晚才开始和他们一起玩,主要是事先没有时间,并意识到它可以让我免去繁琐和耗时的样板。
这是一个指标,除其他外,我有时也“错误地学习”了 Rust,后来意识到它实际上可以更容易地完成。所以我对此的看法是:最好通过适当的时间和反思来学习 Rust。通常我不建议走和我一样的路,除非你喜欢挑战。
我想说的是,在那之后,大部分的实际学习都是生态系统本身。作为一种非常有表现力的语言,Rust crates 作者设计了使用他们的代码的“方法”,有时它会很自然,有时需要一段时间才能习惯它们。但是你对它们了解得越多,你就越能理解为什么它们是这样设计的。
时间已经过去了,我最终想分享的是,Rust 需要适当的时间、反思和思维方式的转变。 几个月前您甚至看不到一些深刻的好处,这绝对是正常的。 没有神奇的快进学习按钮。 对于经验丰富的开发人员来说,这甚至比新手更难,因为我们都从以前的语言(在我的例子中是 ActionScript、PHP、Java 和 JavaScript / TypeScript)中带来了以前的习惯。
但是,一个显着的区别在于可用的学习资源:至少可以说,当我开始时,教程和文档通常很少。 到目前为止,我看到越来越多的内容可供新手使用,更准确的文档和书籍,每周都会出现新的教程。
这是一件非常好的事情。
这值得你花时间吗?
剧透警报:确实如此😉
让我们看看为什么!

“I’m late! I’m late for a very important date! No time to say “Hello”, goodbye! I’m late, I’m late, I’m late!” ― White Rabbit
一次编写,到处构建⚙️
我们以前听说过,对吧?
但这一次也许是真的。
当然,我一开始一直在挣扎,有时我仍然在使用 Rust 时认知精疲力尽,但最后,它从未让我失望:超过编译器要求,在 Rust 中从来没有“你不能那样做”的时刻。
在您的这个特定用例中,生态系统可能还不成熟,它可能很难、压倒性或只是为时过早?当然。它需要你大量的阅读和实验吗?确实。
但最终一切都可以完成。
仅仅是因为 Rust 可以在各种平台上编译为本机代码,并且对 FFI 具有一流的支持,这意味着它可以与大多数语言(如果不是任何其他语言)对话。
我知道只要付出时间和精力,它就可以帮助我构建任何东西。
设置整个服务器基础架构?当然。
编写自定义 Flutter 插件、原生 Nodejs 模块或诸如此类的东西?是的。
甚至构建一个视频游戏、一个嵌入式设备......你的名字!
可能甚至建造一个连接到月球的烤面包机,谁知道呢。
编译时错误和安全☔
仅仅是因为,默认情况下,Rust 中根本不存在大量错误。
它的核心支柱之一是所有权和借用模型:编译器基本上会在任何时候强制您的变量被正确分配、在函数中传递、引用和使用。
它在细节上非常微妙,但本质上非常简单:您只能一次在一个地方改变一个变量,或者一次从多个地方读取,但永远不要同时做这两个。
因此,当变量超出范围时,可以自动释放内存,而无需垃圾收集器。
悬空指针、释放后使用、双释放、空指针异常等也一去不复返了。
在使用 Rust 一年多一点的时间里,我的 Web 服务几乎没有运行时错误。 很少有不同的,我可能可以用手指数数,认真的。
一旦编译,通常它就可以工作了™。
类似于 C 和 C++ ⚡ 的性能
Photo by Marc-Olivier Jodoin on Unsplash
简单地说:它快得离谱。
这意味着,例如,来自 Nodejs,在 Rust 中,即使我过度分配内存(克隆它直到你成功®)或编写优化不足的代码,它仍然平均比精心设计的速度快 5 到 20 倍 和优化的 JavaScript 代码。 为了降低内存消耗。
小轶事:我第一次查看数据反序列化吞吐量(使用 serde)时,我以为我在控制台输出中打错了,因为我的输入是一大块数据,结果显示在……以纳秒为单位。 我一遍又一遍地检查并运行它,直到我意识到一切都很好。 这就是它的速度。
“谁去那里? 是敌是友?” 问哨兵🎭
- 照片由 @huanshi 在 Unsplash 上拍摄
和编译器?在最初的几周内会感到很烦人。
这绝对是几个月的障碍(我会说是对自己的生产力)。但最终成为某种最好的朋友。
编译器错误描述性过强,以至于它通常提供直接复制和粘贴解决方案,并附有解释。
每当我疲倦而遗漏某事或做事不当时:
编译器在那里努力提醒我。
同样由于 Rust 的严格性,我应该提到我现在花更多的时间编写断言实际业务逻辑的测试,而不是断言我对语言行为方式的假设的测试。
在其他语言中,作为开发人员,我们实际上自己持有不变量。必须记住这种方法在这种情况下不能正常工作,记住这种变量类型在与另一种类型相比时表现得非常狂野。在 Rust 中,一切都是无聊的类型。默认情况下,除了让它正确之外别无他法。
它勾起了你的好奇心?
看一看阿莫斯的这篇优秀文章以获得更深入的解释👇
混乱中的宁静🤸♂️
重构是一种幸福。 简直是小菜一碟🍰。
大多数时候它只是遵循编译器的指令。
由于大多数错误发生在 Rust 的编译时,因此一旦编译,任何东西都不太可能发生中断或倒退。
对于我使用过的其他语言,我不能完全肯定。 我什至知道我在说什么吗? 问问我以前的队友谁是“RefactoMan”。
没有工具的工匠什么都不是🧰
- 谷仓图片在 Unsplash 上的照片
工具也是 Rust 感觉舒适、高效和实用的地方:例如,单元测试、文档生成、代码格式化程序和 linter 是内置的。
默认情况下它就在这里。
而且还有很多很多的工具可供使用。
举些例子:
- - see generated assembly code for your program ? 👉 cargo-asm
- - fuzz your tests ? 👉 cargo-fuzz
- - timely compare 2 scripts execution ? 👉 hyperfine
- - profile your code ? 👉 flamegraph
- - enforce valid SQL queries at compile time ? 👉 sqlx
- - enforce valid HTML template at compile time ? 👉 yarte
- - use advanced tracing and telemetry ? 👉 opentelemetry
etc …
心态转变💭
不仅如此,我个人觉得今年我对计算机科学的了解比以往任何时候都多。 并不是特别是它以前不可用或记录不足。 它总是触手可及。 这只是因为,在大多数其他语言中,低级细节被抽象掉了,所以没有真正的动力去深入挖掘。
Rust 需要满足如此多的要求来编译代码的好处是它促使你修改你的基础知识。 美妙的V8黑盒不再处理事情了。
好吧,为了清楚起见,让我在这里重新表述一下:Rust 不会强迫你了解每一个潜在的细节,但它会让你非常了解它们。
此外,您将在 Rust 旅程中学到的有关内存安全的所有内容都与语言无关:因此它将对您之后使用的所有其他语言有用。
挑战极限⚗️
我特别喜欢的是 Rust 周围的热情。
许多人正在重新审视或创新以前很难用其他语言正确完成的领域,如果不是不可能的话。
鉴于编译器永远不会让你编译不是内存安全的代码,它提供了一个“安全网”上下文来试验疯狂的东西(尤其是多线程的)。
一个很好的例子是 rayon,这是一个 crate,它允许您通过简单地更改一行代码来并行化 CPU 密集型任务的迭代。
快速成长
想一想:
9 年前:由 Mozilla Research 孵化。
7 年前:它达到了第一个稳定版本。
4 年前:它正式开始支持 async-await 语法。
今天:它已经提供了成熟的生产就绪服务器解决方案。
好吧,我不了解你,但我不记得有一个编程语言生态系统发展得如此之快,除了当时的 JavaScript。
有趣的事实是,您实际上可能已经使用了一些,甚至没有意识到它。例如,您是否知道一些 Rust 已经进入:Dropbox、Figma、NPM、Microsoft、CloudFlare、Facebook、Amazon、Discord 和 Linux 内核?
生态系统仍有很多需要改进的地方:
本周 Rust 和 crates.io 是测量温度的好方法。
哦,还有一些网站跟踪它的演变,通常标记为:arewegameyet、areweguiyet、arewewebyet 等。
这可以很好地让您了解 Rust 是否已为您的下一个项目做好准备,或者需要一些额外的成熟度。
生产力🏃
所以一般来说,我将其总结为一个整体的方式:
值得花时间提前吗?
尤其是在最初的几个月里,在 Rust 中执行日常任务可能会花费通常执行它们的时间的三倍。随着一项改进,差距最终缩小了:例如,现在我可以像使用 Nodejs 一样快地使用 Rust 设置一个成熟的 REST API。只是花了更长的时间才到达那里。
它基本上是在编译时预先交易时间,
您最终会在运行时节省调试费用。
到目前为止,我个人更喜欢这种方法。
还记得那个导致你的脚本异常失败的小错误吗?还记得你花在调试上的时间吗?几天,几周?
问问自己,您是否愿意在前期投入更多时间。
这也是 Rust 的全部意义所在。
所以让我们总结一下我的收获
对于今天想开始 Rust 的人:
- 不要急于求成:按照自己的节奏学习,适当的时间和反思。
- 摒弃以前的习惯,避免系统地与其他语言进行比较:这需要转变思维方式。
- 不要与编译器对抗:尽早接受它的建议。
- 不要试图过早地进行过度优化:写一些先编译的东西,然后再提高它的效率。
- 从小处着手,随着时间的推移而成长:找到您喜欢的主题的教程,这些教程可以让您快速入门,并在您的旅程中阅读 Rust 书籍。
- 不要让你的生活变得复杂:a.k.a 在没有经验的情况下使用它来为一个期望很高但期限很短的客户使用它。
- 玩得开心,实验!
结束语💬
既然你做到了最后,
谢谢你的时间,我希望你喜欢这个阅读🙂
我实际上有几篇关于实际 Rust 编程的文章,
我希望尽快交付。
直到下一次,大家保重!
原文:https://romain-kelifa.medium.com/after-one-year-of-rust-7cef608fef68
- 165 次浏览
【Rust架构】Rust web框架比较
目录
- 服务器框架
- 过时的服务器框架
- 客户框架
- 过时的客户框架
- 前端框架(WASM)
- 补充库
- WebSocket
- 模板
- 对照
- 高级框架
- 低级框架
- 前端框架
- 中间件和插件
- Websocket库
- 资源
- 博客文章
- 演示
- 使用Rust的真实世界Web项目
- JS&asm.js&WASM
Server frameworks
使用Rust构建Web应用程序有几个有趣的框架:
- actix-web (homepage / repository / documentation / user guide)
- gotham (homepage / repository / documentation / examples)
- iron (homepage / repository / documentation)
- nickel (homepage / repository / documentation)
- rocket (homepage / repository / documentation)
- rouille ( - / repository / documentation)
- Thruster ( - / repository / documentation / examples)
- Tide ( - / repository / documentation / examples)
- tower-web ( - / repository / documentation / examples)
- warp ( - / repository / documentation / examples)
如果您需要更低级别的控件,可以在这些库之间进行选择:
- hyper (homepage / repository / documentation)
- tiny-http ( - / repository) / documentation)
- tk-http ( - / repository / - )
- h2 ( - / repository / - )
过时的服务器框架
Client frameworks
To build web clients with Rust, you can choose between these libraries:
- actix-web (homepage / repository / api docs)
- reqwest (- / repository / documentation)
- hyper (homepage / repository / documentation)
- jsonrpc (- / repository / documentation)
Outdated client frameworks
Frontend frameworks (WASM)
Since WASM support is available in most browsers we can use Rust to build web applications :)
- stdweb ( - / repository / documentation ) A standard library for the client-side Web
- yew ( - / repository / documentation ) - A frontend framework inspired by Elm and React (based on stdweb)
- percy ( homepage / repository / - ) - A modular toolkit for building isomorphic web apps
- seed ( homepage / repository / - ) - A Rust framework for creating web apps
- draco ( - / repository / documentation ) - A frontend framework inpired by Redux and Elm
- smithy ( - / repository / - documentation ) - A front-end framework
- squark ( - / repository / documentation ) - Rust frontend framework, for web browser and more.
- ruukh ( - / repository / documentation ) - A frontend framework inspired by Vue and React
- willow ( homepage - / repository / - ) - A frontend framework inspired by Elm
- dodrio ( - / repository / documentation ) - A fast, bump-allocated virtual DOM library.
- sauron ( - / repository / documentation - Sauron is an html web framework for building web-apps. It is heavily inspired by elm.
Supplemental libraries
Websocket
- websocket (homepage / repository / documentation)
- ws-rs (homepage / repository / documentation)
- tungstenite ( - / repository / documentation)
- tk-http ( - / repository / - )
- actix-web (homepage / repository / documentation)
Templating
- tera (homepage / repository / documentation)
- mustache (- / repository / documentation)
- liquid (- / repository / - )
- handlebars (- / repository / documentation)
- horrorshow (- / repository / documentation)
- maud (homepage / repository / documentation)
- askama (- / repository / - )
- stpl (- / repository / - )
- ructe (- / repository / documentation )
- typed-html (- / repository / documentation )
对照
高级框架
| Name | rocket | iron | actix-web | nickel | gotham | rouille | Thruster | jsonrpc | ease |
|---|---|---|---|---|---|---|---|---|---|
| License |  |
 |
 |
 |
 |
 |
 |
 |
 |
| Github Stars |  |
 |
 |
 |
 |
 |
 |
 |
 |
| Contributors |  |
 |
 |
 |
 |
 |
 |
 |
 |
| Server | yes | yes | yes | yes | yes | yes | yes | no | no |
| Client | no | no | yes | no | no | no | no | yes | yes |
| Base framework | hyper | hyper | tokio | hyper | hyper | tiny-http | tokio | hyper | hyper |
| HTTPS support | yes | yes | no | yes | ? | - | - | ||
| HTTP/2 support | ? | yes | ? | no | ? | ? | ? | ||
| Async | no | yes | yes | yes |
Low-Level Frameworks
| Name | hyper | h2 | tiny-http | tk-http |
|---|---|---|---|---|
| License |  |
 |
 |
 |
| Github Stars |  |
 |
 |
 |
| Contributors |  |
 |
 |
 |
| Server | yes | yes | yes | yes |
| Client | yes | yes | ? | yes |
| HTTPS support | yes | no | yes | yes |
| HTTP/2 support | solicit | yes | ? | no |
| Async | yes | yes | yes |
Frontend Frameworks
| Name | yew | stdweb | percy | dodrio | sauron | seed | ruukh | draco | squark | willow | smithy |
|---|---|---|---|---|---|---|---|---|---|---|---|
| License |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Github Stars |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Contributors |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Stable Rust | yes | yes | no | ? | no | yes | no | yes | no | no | no |
| Base framework | stdweb | - | wasm-bindgen | wasm-bindgen | wasm-bindgen | wasm-bindgen | wasm-bindgen | wasm-bindgen | wasm-bindgen | wasm-bindgen | wasm-bindgen |
| Virtual DOM | yes | ? | yes | yes | yes | yes | yes | yes | yes | ? | ? |
Middleware & Plugins
| Name | iron | gotham | nickel | rouille | actix-web |
|---|---|---|---|---|---|
| Static File Serving | yes | no^ | yes | n/a | yes |
| Mounting | yes | yes | yes | n/a | yes |
| Logging | yes | yes | no | n/a | yes |
| JSON-Body-Parsing | yes | yes | yes | n/a | yes |
| Sessions | yes | yes | ? | n/a | yes |
| Cookies | yes | yes | ? | n/a | yes |
| PostgreSQL middleware | ? | no^ | yes | n/a | yes |
| SQLite middleware | ? | no^ | yes | n/a | yes |
| Redis middleware | ? | no^ | yes | n/a | yes |
| MySQL middleware | ? | no^ | yes | n/a | yes |
(^ Planned in current roadmap)
Websocket Libraries
| Name | websocket | ws-rs | twist | tungstenite | tk-http | actix-web |
|---|---|---|---|---|---|---|
| License |  |
 |
|
 |
|
|
| Github Stars |  |
 |
 |
 |
|
|
| Contributors |  |
 |
 |
 |
|
|
| Server | yes | yes | yes | yes | yes | yes |
| Client | yes | yes | yes | yes | yes | yes |
| Base framework | - / tokio | mio | tokio | - / tokio | tokio | tokio |
| Async | no / yes | yes | yes | no / yes | yes | yes |
Examples
To compile or run the examples use Cargo. First clone this repo
git clone https://github.com/flosse/rust-web-framework-comparison
cd rust-web-framework-comparison/
and change to the desired frameworkd directory (e.g. cd iron/) and type
cargo run --example hello_world
Then visit http://localhost:3000 to see the result.
Resources
Blog posts
2018
- Lessons learned on writing web applications completely in Rust
- Introducing Ruukh Framework
- Baby’s First Rust+WebAssembly module: Say hi to JSConf EU!
- Mix Rust Code (WebAssembly) with Vue Component
- Wicked Fast Web Servers in Rust
- Migrating to Actix Web from Rocket for Stability
- Creating a Rusty Rocket fuelled with Diesel
Until 2017
- Dose Response ported to WebAssembly!
- Rust and the case for WebAssembly in 2018
- wasm32-unknown-unknown landed & enabled
- How to Deploy a Rocket Application to Heroku
- Rust to WebAssembly, Made Easy
- Rust for the web
- Rocket on Fedora
- Announcing Gotham - A flexible web framework for stable Rust that does not sacrifice safety, security or speed.
- Announcing cargonauts - A Rust async web framework
- Writing a GitHub webhook with Rust! Part 1: Rocket
- Hello, Botket! (Rocket)
- Launching a URL Shortener in Rust using Rocket
- Rocket + sodiumoxide = ♥
- The Path to Rust on the Web
- Rendering Vector Map Tiles (Rust + asm.js demo)
- Compiling to the web with Rust and emscripten
- Basic 2FA in Rocket
- Building high performance REST APIs with Rust and Rocket
- Rocket Rocks! Using FromFormValue Traits to protect your website
- Building an Asynchronous Hyper Server
- JWT & Access Roles in Rocket
- Writing a basic JSON response web server in Rust using Iron
- Diesel Powered Rocket
- Using Stainless with Rocket
- Integration testing a service written in Rust and Iron
- Actually using Iron: A grumpy introduction to web development in Rust
- Using Rust for Webdev as a Hobby Programmer
- My adventures in Rust webdev
- Rust’s Iron Framework: First impressions
- Rust for Node.js developers
- A Rust-powered public web page in 5 minutes
- Rust and Rest
- Shipping forgettable microservices with Rust
- Writing a simple REST app in Rust
- Getting started with Rust
- Let's Build a Web Server in Rust
- Creating a basic webservice in Rust
- Iron on uWSGI
- Deploying a Rust App to Google App Engine
- async hyper
- Trying Rust for web services
- Are we web yet?
- Reimplementing ashurbanipal.web in Rust
- A web app with Nickel: From first line to Heroku deployment
- What features Iron does not have compared to a web server like nginx?
- Build an API in Rust with JWT Authentication using Nickel.rs
- Selective Middleware for Iron
- Rust for the Web - RESTful API in Rust, impressions
- Rust for Node developers
Demos
- exoskeleton - Iron
- Example webapp using React + Webpack - Iron
- rustwebapp - Iron and Postgres (r2d2)
- webrust - Iron and Postgres (r2d2)
- httptest - Iron
- nickel-todo-backend - Nickel and Postgres (r2d2)
- rust-playground - Iron
- rust-web-example - Iron + Diesel (r2d2) + Serde
- websocket chat - Actix: Browser Websocket + tcp chat
- diesel - Actix + Diesel
- json - Actix + serde_json or json_rust
Real-world web projects using Rust
- paste.rs - Rocket
- Portier - Iron and Redis
- yaus - Iron and SQLite
- racerd - Iron
- rust-passivetotal - Hyper
- mars - Hyper
- openfairdb - Rocket and Neo4j (r2d2)
- ruma - Iron and Posgres (diesel + r2d2)
- html2pdf - Iron
JS & asm.js & WASM
- hellorust.com - a website with news, resources and demos
Examples
- rust-webapp-template - Template project for Rust web app using stdweb
- rust-todomvc - an example application build with webplatform
- wasm-experiments - experiments with
wasm32-unknown-unknown
Benchmark
- TechEmpower Web Framework Benchmarks
- benchmarks - Rust web frameworks benchmarks
- which_is_the_fastest - Measuring response times (routing times) for each framework (middleware). Each framework has to have two features; routing and parsing path parameters.
- 3069 次浏览
【Rust编程】在Rust中使用C库
使用bindgen的FFI实用指南(第1部分,共2部分)
今天我想深入探讨一下我们在尝试用Rust重写IoT Python代码时遇到的一个困难:具体地说是FFI,或者“外文函数接口”(Foreign Function Interface)——允许Rust与其他语言交互的位。一年前,当我试图编写与C库集成的Rust代码时,现有的文档和指南常常给出相互矛盾的建议,我不得不自己一个人跌跌撞撞地完成这个过程。本指南旨在帮助将来的rustacean完成将C库移植到Rust的过程,并使读者熟悉在进行同样操作时遇到的最常见问题。
在本指南中,我们将讨论如何使用bindgen使C库函数暴露为Rust。我们还将讨论一下这个自动工具集的局限性,以及如何检查您的工作。公平警告:正确实施外国金融机构是非常困难的模式。如果你是新手,请不要从这里开始。仔细阅读这本书,写一些练习代码,在完全熟悉借阅检查器之后再回来。
动机
为了证明这一点,我需要解释一下为什么我们德韦洛一开始就需要这么做。
对于我们的重写项目,我们希望与供应商提供的C库集成,该库负责通过标准供应商指定的协议通过串行端口与我们的Z-Wave芯片进行通信。这种串行通信协议很复杂,很难正确实现,而且还受到严格的时间限制——发送到串行端口的字节基本上是通过无线电直接传输的。在错误的时间发送错误的字节可能会完全挂起无线电芯片。有一个长达几百页的参考文档,包含传输和确认、重传逻辑、错误处理、定时间隔等的规范。最初的Python代码从零开始(错误地)实现了这个协议,这个实现代表了遗留堆栈中相当大的一部分bug。除此之外,无线芯片组供应商正在推迟认证,除非我们能够证明我们正确地实现了协议。巧合的是,提供的参考库(用C实现)被保证符合规范。很明显,供应商C代码似乎是商业成功的最短路径。
Rust本机支持链接C库并直接调用它们的函数。当然,因此导入的任何函数都需要实际调用unsafe关键字(因为Rust不能保证其不变量或正确性),但这给我们带来了不便,我们可以稍后再使用。
Rust Nomicon将告诉您,只要名称和签名完全对齐,就可以通过在extern块中声明来导入函数定义或其他全局符号。这在技术上是正确的,但不是很有帮助。手工输入函数定义是完全愚蠢的,而且当我们有一组非常好的包含声明的头文件时就没有意义了。相反,我们将使用一个工具从库的C头文件生成锈迹签名。然后我们将运行一些测试代码来验证它是否正常工作,调整一些东西直到看起来正确为止,最后将整个东西烘焙到一个Rust的板条箱中。我们开始吧。
宾根(Bindgen)
最常用的工具是bindgen,它可以从C头生成锈迹签名。我们的目标是创造一个绑定.rs表示库的公共API(其公共函数、结构、枚举等)的文件。我们将配置板条箱以包含该文件。一旦构建了板条箱,我们就可以将该板条箱导入到任何项目中,以调用C库的函数。
您需要:
- 正常工作的货物装置。我假设如果你编译的是Rust代码,你就有这个。
- 一个正在运行的C编译器和pkg配置,用于依赖项解析。
- 与要使用的库函数对应的头文件。
- 如果您有很好的源代码,本例假设您是从源代码构建库。否则,如果链接到的静态或动态库不在系统路径中,则需要该库的路径。
- 与库的API大小相对应的耐心程度。
安装命令行bindgen工具非常简单:
cargo install bindgen
在我的Debian笔记本电脑上,我还需要手动安装clang,尽管您的里程数可能会有所不同。
设置你的板条箱(crate)
我们的新库板条箱将包含肮脏的业务建设和出口本机C库的不安全功能。同样,将所有安全的包装器留给另一个板条箱—这不仅加快了编译速度,而且还使其他板条箱作者能够最少地导入和使用原始的c绑定。FFI板条箱的标准Rust命名约定为lib<XXXX>-sys。
我们要创造一个内部版本.rs将与cc板条箱一起使用的文件,用于编译和链接我们的bindgen导出。让我们将库源代码放在一个名为src的子目录中,并将相关的include文件放在一个名为include的子目录中。接下来,让我们确定货物.toml已设置:
[package]
name = "libfoo-sys"
version = "0.1.0"
links = "foo"
build = "build.rs"
edition = "2018"[dependencies]
libc = "0.2"[build-dependencies]
cc = { version = "1.0", features = ["parallel"] }
pkg-config = "0.3"
接下来我们将填充内部版本.rs文件。下面看起来有点奇怪-我们正在编写一个Rust程序,它将输出一个脚本到stdout;cargo将直接使用这个脚本来构建我们的板条箱。
如果你链接的是一个已经编译过的库,保证在系统路径中,你的内部版本.rs可能就这么简单:
fn main() {
println!("cargo:rustc-link-lib=foo");
}
不过,大多数情况下,您至少需要使用某种包配置来确保库已实际安装并且链接器可以找到它。在许多情况下,您的库足够小,可以由cargo本身构建为静态库。pkg配置板条箱有助于库和依赖项配置,cc处理从cargo内部构建C代码的脏活。两个板条箱在输出货物所需的行之前都运行配置和构建步骤。在我们的示例中,我们的源代码使用zlib,因此我们使用pkg config来查找和导入适当的版本。下面的示例代码还显示了如何添加编译器标志和预处理器定义。
fn main() {
pkg_config::Config::new()
.atleast_version("1.2")
.probe("z")
.unwrap(); let src = [
"src/file1.c",
"src/otherfile.c",
];
let mut builder = cc::Build::new();
let build = builder
.files(src.iter())
.include("include")
.flag("-Wno-unused-parameter")
.define("USE_ZLIB", None); build.compile("foo");
}
最后,你需要一个src/自由卢比文件来编译我们的绑定。在这里,我们将禁用与Rust不一致的C命名约定的警告,然后只包含生成的文件:
#![allow(non_upper_case_globals)]
#![allow(non_camel_case_types)]
#![allow(non_snake_case)]use libc::*;include!("./bindings.rs");
生成绑定
而bindgen用户指南似乎指导您在其中动态生成绑定rs,实际上,您需要在将生成的输出释放到板条箱之前对其进行编辑。通过命令行生成一个或多个文件,并将输出提交到存储库,这将为您提供最大的控制。
最初的生成尝试可能如下所示:
bindgen include/foo_api.h -o src/bindings.rs
对于一个包含多个API调用的真正头,不幸的是,这将生成比我们想要或需要的更多的定义。生成部分绑定.rs因为我们在德韦洛的项目更接近于此:
bindgen include/foo_api.h -o src/bindings.rs '.*' --whitelist-function '^foo_.*' --whitelist-var '^FOO_.*' -- -DUSE_ZLIB
说服生成器只提供所需的内容,而不吐在未定义的符号上,这是一个反复试验的过程。考虑分阶段生成并连接结果。
它很强大,但并不完美
当您将头传递给bindgen时,它将调用Clang预处理器,然后贪婪地转换它能看到的每个符号定义。您需要在命令行进行调整,并重构结果输出。
原始Makefile/CMake extras
在bindgen命令行上的--之后,您可以添加在针对库构建时通常添加到编译器的任何标志。有时,这些将是额外的include路径,有时,当标头具有#ifdef保护的定义时,它们将是必需的。对于我们的供应商库,未能定义OS\u LINUX隐藏了一堆我们需要的符号。(什么,你认为遗留代码会使用标准的编译器定义,比如linux,而不是编造东西吗?抱歉,喜剧时间在楼下和楼上。)如果您生成的输出神秘地缺少函数,请检查您的定义。
包含标准标头的标头
Bindgen非常积极地为预处理器输出中的每个可用符号生成定义,甚至为不需要的可传递的系统特定依赖项生成定义。这意味着如果你的头文件包含stddef.h或time.h(或者包含另一个包含stddef.h或time.h的头文件),你将在生成的输出中得到一堆额外的垃圾。编译C++代码时更糟,因为C++编译器显然必须导出STD中使用的每个符号,即使它不是必需的或需要的。
您的板条箱应该只公开库API中的内容,而不是系统头文件或生成代码的标准库中的内容。这是一个痛苦,特别是如果您的库的函数和常量不遵循任何类型的命名约定。唯一的解决方法是使用白名单regex和大量的尝试和错误。
预处理器#defines
#define FOO_ANIMAL_UNDEFINED 0 #define FOO_ANIMAL_WALRUS 1 #define FOO_ANIMAL_DROP_BEAR 2/* Argument should be one of FOO_ANIMAL_XXX */ void feed(uint8_t animal);
这看起来是人为的,但这是一个模糊版本的模式,在我们的供应商C库中很普遍。
在C语言中,这样做很好,因为当您将头文件包含到源代码中时,当函数调用它时,您可以直接使用FOO\u ANIMAL\u WALRUS之类的东西。C编译器会隐式地将文字1转换为uint8\t,代码就可以运行了。当然,为了清晰起见,最初的作者应该创建一个enum typedef并使用它,但是他们没有,这仍然是我们必须处理的合法C代码。
pub const FOO_ANIMAL_UNDEFINED: u32 = 0;
pub const FOO_ANIMAL_WALRUS: u32 = 1;
pub const FOO_ANIMAL_DROP_BEAR: u32 = 2;extern "C" {
pub fn feed(animal: u8);
}
尽管bindgen足够聪明,可以将符号识别为常量,但仍然存在一些问题。首先,bindgen必须猜测每个FOO\u ANIMAL\u XXX的类型。在这种情况下,显然是猜测了u32(它不仅与我们的函数参数不匹配,而且在技术上也是错误的)。这导致了另一个问题:在调用feed时,Rust将要求我们显式地将FOO\u ANIMAL\u WALRUS转换为u8。不是很符合人体工程学,是吗?要解决这个问题,我们需要更改生成的常量的类型以匹配函数定义。稍后我们将在安全包装中修复枚举问题。
有些结构应该是不透明的
我们的vendored库为除初始化之外的几乎所有函数传递一个指向上下文对象的指针。(现在我们称之为foo\u ctx\t)这是一种广泛使用的模式,非常合理。但是由于一个实现缺陷,我们的头文件定义了foo\u ctx\u t而不是向前声明它。不幸的是,这泄漏了foo\u ctx\t的内部结构,然后这种泄漏会间接地迫使我们知道并定义一堆我们不关心的其他依赖类型。
Rust实际上不允许对结构进行单独的声明和定义。与C不同,我们不能在Rust中声明foo\u ctx\t而不为其提供定义,而且Rust编译器必须识别foo\u ctx\t名称,以便将指向它的指针用作函数arg。但是我们可以使用变通方法来避免完全定义它。两者都不是完美的,但在撰写本文时,有两种选择至少在实践中起作用。
我们可以将结构定义替换为没有变量的枚举类型,如果您不小心尝试构造它或将它用作指针目标以外的任何对象,则很容易出现编译错误。这让类型纯粹主义者感到不安,因为从技术上讲,我们在对编译器撒谎,但它确实有效:
pub enum foo_ctx_t {}
或者我们可以用一个私有的零大小类型字段替换它的内部。这是bindgen默认的功能,只要不依赖mem::size\u of:
pub struct foo_ctx_t {
_unused: [u8; 0],
}
常量正确性
Bindgen将C常量指针转换为Rust常量*,将未修饰的C指针转换为mut*。如果原始代码是const correct,那么这个结果就很好了。如果没有,它可能会导致头痛以后当试图创建安全的包装。如果可能,修复库。
下面的例子可以很容易地用在一个Rust不安全的块中,对时间的正常(不变)引用和对tm的可变引用:
// Generated from <time.h>
extern "C" {
pub fn gmtime_r(_t: *const time_t, _tp: *mut tm) -> *mut tm;
}
从技术上讲,您不必修改C库来更改外部定义中指向const*的指针。事实上,C库的符号表甚至没有参数列表,所以Rust的链接器根本无法确认函数参数是否正确(这是C++符号的情况,谢天谢地)。如果您确实修改了Rust指针类型,那么您将负责验证const指针的不变量对于库实际上是正确的。
锋利的边缘
如果您的函数有错误的返回值,请现在帮自己一个忙,确保每个函数都附加了#[must_use]注释。如果调用者忘记检查返回值是否有错误,这至少会给出一些指示,并且在以后将所有内容包装到安全层时会有所帮助。
写一个自述文件.md详细说明如何调用bindgen的文件,并将其提交到存储库。相信我,等你意识到有东西不见了你会想要这个的。
添加几个单元测试来测试是否正常,然后尝试运行cargo测试。Bindgen创建了一些自己的测试,以确保生成的结构对齐是正确的。您还可以运行cargo doc——在您的板条箱上打开,以获得您正在输出的内容的高级视图,并再次检查您是否无意中暴露了错误的内容。
尽管如此,这些手动步骤是必要的,因为bindgen正在尽其所能地利用它所拥有的信息。生成过程将暴露C库中的每个小结构问题。
当您全部完成时,希望您将留下一个不太令人讨厌的Rust包,它通过不安全的Rust暴露您的原始库API。你已经成功了一半!接下来,我们将讨论如何使用这些绑定,并在符合人体工程学和安全的包装器后面保护它们,以便我们的应用程序代码不会错误地使用它们。
原文:https://medium.com/dwelo-r-d/using-c-libraries-in-rust-13961948c72a
本文:http://jiagoushi.pro/node/1450
讨论:请加入知识星球【全栈和低代码开发】或者微信【it_training】或者QQ群【11107767】
- 190 次浏览
【Rust编程】用Rust包装不安全的C库
一个实用的指南,以FFI不让你的指节流血(第2部分,共2)
在第1部分中,我们探讨了如何获取一个C库并为它编写一箱不安全的Rust绑定。使用这个板条箱可以通过“不安全”直接访问库中的函数和其他符号,但必须在应用程序代码中的任何地方使用不安全的块并不是很符合人体工程学的。我们需要一些办法来阻止这种疯狂。
在本文中,我们将探讨如何包装这些函数,并使它们能够安全地正常使用。我们将讨论如何定义处理初始化和清理的包装器结构,并描述一些特性,这些特性描述了应用程序开发人员如何安全地将库与线程一起使用。我们还将讨论如何将函数的随机整数返回转换为符合人体工程学的类型检查结果,如何将字符串和数组与C世界进行转换,以及如何将从C返回的原始指针转换为具有继承生存期的作用域对象。
这一步的总体目标是深入研究C库的文档,并使每个函数的内部假设明确化。例如,文档可能会说函数返回指向内部只读数据结构的指针。该指针在程序生命周期内有效吗?它被限定在某个范围内还是被初始化了?最后,我们将有一套包装器,使这些假设对Rust可见。然后,我们将能够依靠Rust的借阅检查器和强制错误处理来确保每个人都正确地使用库,即使是在多个线程中。
添加枚举
在上一篇文章中,我们讨论了一个以枚举类型作为参数的示例函数。这是清理过的bindings.rs代码:
pub const FOO_ANIMAL_UNDEFINED: u8 = 0;
pub const FOO_ANIMAL_WALRUS: u8 = 1;
pub const FOO_ANIMAL_DROP_BEAR: u8 = 2;extern "C" {
/// Argument should be one of FOO_ANIMAL_XXX
pub fn feed(animal: u8);
}
等一下。函数签名说它需要一个u8,但是文档说参数应该是FOO\u ANIMAL\u XXX中的一个(为了我们自己的理智,假设它可以安全地处理未定义的情况)。如果我们让我们的安全代码以任意的u8作为输入运行,这不仅令人困惑,而且有潜在的危险。听起来我们的安全包装应该采取动物枚举和转换它。
我们可以手工写这个枚举。但是让我们使用enum_原语板条箱来给我们一些额外的灵活性。(为了简洁起见,我省略了rustdoc字符串,不过您应该在实际代码中包含它们):
use enum_primitive::*;enum_from_primitive! {
#[derive(Debug, Copy, Clone, PartialEq)]
#[repr(u8)]
pub enum Animal {
Undefined = FOO_ANIMAL_UNDEFINED,
Walrus = FOO_ANIMAL_WALRUS,
DropBear = FOO_ANIMAL_DROP_BEAR,
}
}
因为我们将结构标记为“representable as a u8”,所以一个简单的cast就足以将动物转换成u8。现在我们可以这样写我们的安全包装:
pub fn feed(animal: Animal) {
unsafe { libfoo_sys::feed(animal as u8) }
}
enum_primitive板条箱还为我们提供了一些有用的样板函数,用于将u8转换为选项<Animal>。如果函数返回实际应视为枚举类型的u8值,则可能需要这样做。有一个问题:如果提供的数字与枚举值不匹配,则从数字类型的转换可能会失败。这取决于您的代码是否立即展开并惊慌失措,是否用默认值替换None(“Unknown”如果存在可以使用,如果不存在可以添加),或者只是返回选项并让调用者处理它。
返回指针的初始值设定项
在接下来的几个示例中,我将使用一个非常著名和非常粗糙的库作为示例:OpenSSL。(请不要自己为OpenSSL实现绑定;有人已经实现了,而且做得更好。这只是一个很熟悉的例子。)
在使用OpenSSL加密或解密数据之前,首先需要调用一个函数来分配和初始化一些上下文。在我们的示例中,这个初始化是通过调用SSL\u CTX\u new来执行的。执行任何操作的每个函数都会获取一个指向此上下文的指针。当我们使用完这个上下文后,需要使用SSL\u CTX\u free清理和销毁上下文数据。
我们将创建一个结构来包装此上下文的生存期。我们将添加一个名为new的函数,它为我们进行初始化并返回这个结构。所有需要上下文指针的C库函数都将包装为trust函数taking&self并在结构上实现。最后,当我们的结构超出范围时,我们希望锈迹能自动清除。希望这应该是一个熟悉的软件模式:它是RAII。
我们的示例可能如下所示:
use failure::{bail, Error};
use openssl_sys as ffi;pub struct OpenSSL {
// This pointer must never be allowed to leave the struct
ctx: *mut ffi::SSL_CTX,
}impl OpenSSL {
pub fn new() -> Result<Self, Error> {
let method = unsafe { ffi::TLS_method() };
// Manually handle null pointer returns
if method.is_null() {
bail!("TLS_method() failed");
} let ctx = unsafe { ffi::SSL_CTX_new(method) };
// Manually handle null pointer returns here
if ctx.is_null() {
bail!("SSL_CTX_new() failed");
} Ok(OpenSSL { ctx })
}
}
我将ffi后面的C库调用命名为namespacking,以便更清楚地了解我们导入的内容与我们在包装器中定义的内容。我也作弊了一点,并使用保释失败板条箱-在真正的代码中,你会想定义一个错误类型,并使用它。是的,它看起来有点恶心,因为我们没有从我们的回报拆解选项类型的细节。我们必须手动检查一切。
请记住:包装不安全函数意味着您正在进行验证空指针和检查错误的艰苦工作。这正是包装器必须正确处理的类型。早期的恐慌远胜于默默地传递空指针或无效指针。我们也不能允许ctx指针从结构中复制出来,因为我们只能保证它在结构仍然存在时是有效的。
通过impl Drop的析构函数
另一端是清理。铁锈中的毁灭者是通过下降特性来处理的。我们可以为我们的结构实现Drop,这样铁锈就可以适当地破坏我们的句柄:
impl Drop for OpenSSL {
fn drop(&mut self) {
unsafe { ffi::SSL_CTX_free(self.ctx) }
}
}
Rust还可以防止drop被直接调用或两次调用,因此您不必玩一些技巧,比如在释放ctx之后手动将其置空。而且,与C++不同,析构函数不会因为隐形拷贝被创建和删除而被无形调用。
发送和同步
现在有了一个包含指针元素的结构。但是默认情况下,Rust会对如何在线程上下文中使用struct设置一些限制。为什么语言会这样做,为什么这很重要?
默认情况下,Rust假设原始指针不能在线程之间移动(!发送),并且不能在线程之间共享(!同步)。因为你的结构包含一个原始指针,所以它既不发送也不同步。这种保守的假设有助于防止外部C代码在crust提供的那些可爱的线程安全保证上到处乱跑。
如果你的对象没有被发送,那么你在线程程序中处理它的能力就会受到很大的限制——甚至无法将它包装在互斥锁中并在线程之间传递引用。但可能外部文档或对源代码的巧妙检查表明返回的上下文指针在线程之间移动是安全的。它还可以指示使用此上下文指针的函数在线程上下文中使用是否安全,即函数本身是线程安全的。Rust无法为您做出这些决定,因为它看不到库使用这些指针做了什么。
如果你能断言你的每一次使用(内部私有!)指针遵守这两条规则中的任何一条,你都可以直截了当地告诉我。正确地做出这种断言是困难的,如果不是危险的,并且灌输给你适当数量的恐惧Rust需要你使用不安全的关键字。
unsafe impl Send for MyStruct {}
unsafe impl Sync for MyStruct {}
假设您不允许以某种方式(通过访问器方法或通过标记结构成员pub)对指针进行外部访问,那么如果您可以做出以下断言,则可以安全地执行以下操作:
- 如果取消引用指针的C代码从未使用线程本地存储或线程本地锁定,则可以标记struct Send。许多库都是这样。
- 如果所有能够取消引用指针的C代码总是以线程安全的方式(即与safe-Rust一致)取消引用,则可以标记结构同步。大多数遵循此规则的库都会在文档中告诉您,并且它们在内部使用互斥锁来保护每个库调用。
返回指针的函数
假设我们已经用新的和drop实现建立了结构。我们很高兴地翻阅了接受这个上下文指针的函数列表,对于我们想要公开的每一个函数,我们正在针对我们的结构实现一个安全版本,它接受&self。然后我们遇到了这样的事情(为了简单起见是虚构的,但不远):
// Always returns valid data, never fails
SSL_CIPHER *SSL_CTX_get_cipher(const SSL_CTX *ctx);
我们显然不想从包装器中返回原始指针,这不太符合人体工程学。这样做的目的是确保库用户不必使用不安全的软件。
阅读文档后,我们发现SSL\u CIPHER是一个结构,只要SSL\u CTX没有被释放,返回的指针就有效。嘿,听起来像是一辈子的事。所以我们的第一种方法可能是这样的:
pub fn get_cipher(&self) -> &ffi::SSL_CIPHER {
unsafe {
let cipher = ffi::SSL_CTX_get_cipher(self.ctx);
// Dereference the pointer, then turn it into a reference.
// Remember: derefing a pointer is unsafe!
&*cipher
}
}
取消引用然后立即获取指针的地址会创建一个所谓的无限生存期。这不是我们想要的,所以我们立即通过返回类型来约束生存期。我们没有明确指定生存期,但是让我们回顾一下Rust手册中关于生存期省略的规则。在这种情况下,返回值的生存期将被默认约束为与&self的生存期相同。这是一个合理的界限,所以这个实现看起来是安全的。
但我们可以更进一步。SSL\u密码通常用作上下文指针,并具有自己的关联函数。实际上,让我们的安全代码返回对C结构的引用根本不符合人体工程学。我们要返回的是一个Rust结构,它自身的关联行为与C库匹配。但我们也应该保留生存期关联:“只有从中获取密码的OpenSSL对象仍然存在,这个密码对象才有效。”
因此,假设我们已经完成了创建一个密码结构来包装指针的工作,并且我们想告诉Rust这个结构有某种依赖于OpenSSL对象的生存期:
pub fn get_cipher<'a>(&'a self) -> Cipher<'a> {
unsafe {
let cipher = ffi::SSL_CTX_get_cipher(self.ctx);
Cipher::from(&self, cipher)
}
}// Something is missing here...
pub struct Cipher<'a> {
cipher: *const ffi::SSL_CIPHER,
}fn from<'a>(_: &'a OpenSSL, cipher: *const ffi::SSL_CIPHER)
-> Cipher<'a> {
Cipher { cipher }
}
不幸的是,这不会编译,因为Rust说“嘿,你声明了一个与你的结构相关联的生存期,但是它没有在任何地方使用!“所以我们需要以某种方式声明,是的,内部依赖于一个我们不能立即看到的引用。
use std::marker::PhantomData;pub struct Cipher<'a> {
cipher: *const ffi::SSL_CIPHER,
phantom: PhantomData<&'a OpenSSL>,
}fn from<'a>(_: &'a OpenSSL, cipher: *const ffi::SSL_CIPHER)
-> Cipher<'a> {
Cipher { cipher, phantom: PhantomData }
}
您可以将其视为对编译器说:“将此结构视为包含对OpenSSL的引用,其生存期为'a'。这一生从何而来?当我们打电话给我们的发件人时,我们会提供它。
幻影数据实际上并不占用任何空间,它会在编译代码中消失。但它允许编译器对生存期的正确性进行推理。现在,我们的包装器用户不能在释放其父级OpenSSL后意外地持有密码。
可能返回错误的函数
考虑以下C函数:
int foo_get_widget(const foo_ctx_t*, widget_struct*);
我们需要传递一个指针,函数将填充它。如果此函数返回0,则一切正常,我们可以相信输出已正确填充。否则,我们需要返回一个错误。
更符合人体工程学的做法是返回一个拥有数据的结构,而不是要求调用方创建一个可变结构并传递一个mut引用(尽管如果这样做有意义的话,您可以同时提供这两个结构)。
在下面的示例中,我假设自定义错误类型是在其他地方定义的,并且允许从适当的类型进行转换。
use std::mem::MaybeUninit;pub fn get_widget(&self) -> Result<widget_struct, GetError> {
let mut widget = MaybeUninit::uninit();
unsafe {
match foo_get_widget(self.context, widget.as_mut_ptr()) {
0 => Ok(widget.assume_init()),
x => Err(GetError::from(x)),
}
}
}
Ed:感谢reddit/u/Cocalus指出mem::uninitialized()已被弃用。希望我能修好!
上面,widget_struct不实现Default,因为“Default”和零化构造函数都没有意义。相反,我们告诉Rust不要初始化结构内存,因此我们断言外部函数负责正确初始化结构的每个字段。
有些函数不返回任何有用的信息,但仍然可能出错。
int foo_update(const foo_ctx_t*);
您可能会尝试将整数值转换为枚举类型,然后使用它。别那么做!正确编写的代码会在出现故障时返回结果,您也应该这样做。但是“成功”的价值观呢?为此,我们应该使用()告诉调用者没有返回数据。但是调用者仍然需要打开包装或者处理错误。
update(&self) -> Result<(), UpdateError> {
match unsafe { foo_update(self.context) } {
0 => Ok(()),
x => Err(UpdateError::from(x)),
}
}
FFI中的字符串
Rust不像C那样将字符串存储为以null结尾的char缓冲区;它在内部存储缓冲区和长度。因为类型并没有完全对齐,这意味着从Rust字符串的世界移到C char数组,再移回来需要一些技巧。谢天谢地,有一些内置类型可以帮助管理它,但是它们附带了很多字符串。有些转换分配(因为它们需要改变字符串表示或添加终止null),有些则不分配。有时不做拷贝就可以安全地逃脱,有时则不然。文档确实解释了哪个是哪个,但是有很多东西需要通读。这是执行摘要。
如果您以某种方式生成了一个Rust字符串,并且需要将它作为临时const*c\u char传递给c代码(这样它就可以制作一个字符串的副本供自己使用),那么您可以将它转换为CString,然后作为\u ptr调用。如果包装器签名借用了&str,则首先转换为&CStr,然后作为\u ptr调用。这两种情况下的指针只有在Rust引用正常有效时才有效。原始指针剥离了借用检查器的安全性,并要求我们自己维护这个不变量。如果你搞砸了,铁锈帮不了你。
对于从C函数中获取const char*并希望将其转换为Rust可以使用的内容的情况,需要确保它不为null,然后将其转换为具有适当生存期的&CStr。如果你不知道如何表达一个合适的生命周期,最安全的方法就是立即将它转换成一个拥有的字符串!
需要注意的其他事项:
- CString::因为ptr有一把手枪,很难正确使用。阅读文档中标记为WARNING的部分,并确保CString在C代码返回之前一直在作用域中。
- trust字符串可以合法地在中间有一个空的\0字节,但是C字符串不能(因为它会终止字符串)。因此,尝试将&str转换为&CStr或将字符串转换为CString可能会失败。你的代码需要处理这个问题。
- 一旦将原始C指针转换为&CStr,在将其用作本机safe Rust中的&str之前,仍然需要执行(或不安全地跳过)一些验证。C使用任意字符串编码,而Rust字符串总是UTF-8。现在大多数C库都返回有效的UTF-8字符串(ASCII是一个子集,所以即使是传统的应用程序也可以)。允许分配的函数(如CStr::to \u str \u lossy)将在必要时用UTF“替换字符”替换无效字符,而其他函数如CStr::to \u str将只返回一个结果。阅读文档,并根据需要选择正确的函数。
- 如果库返回路径,请在包装器中使用OsString和&OsStr,而不是String和&str。
数组和长度
如果库接受指向T的指针和长度,那么很容易实现一个包装器,该包装器接受一个切片并将其分解为指针和长度。但反过来呢?原来还有一个库函数。请记住检查null,确保大小是元素数,并再次检查返回生存期是否正确。同样,如果不能保证生存期的正确性,只需返回一个拥有的集合,比如Vec。
回调
回调签名通常作为bindgen中的选项<unsafe extern“C”fn…>生成。因此,当您使用Rust编写回调时,显然需要使用不安全的extern“C”来装饰它们(它们不需要是pub),然后当您将它们传递到C库时,只需将名称包装在一些文件中。很简单。
问题是,在C代码中释放恐慌是…好吧,我们就说它是坏的。理论上,恐慌几乎可以发生在Rust代码的任何地方。所以为了安全起见,我们需要把我们的身体包在里面。通常情况下,抓住恐慌是不明智或理智的,但这是例外。没有双关语。
unsafe extern "C" fn foo_fn_cb_wrapper() {
if let Err(e) = catch_unwind(|| {
// callback body goes here
}) {
// Code here must be panic-free.
// Sane things to do:
// log failure and/or kill the program
eprintln!("{:?}", e);
// Abort is safe because it doesn't unwind.
std::process::abort();
}
}
常见模式
在编写这些包装器时,您可能会遇到一些可以在函数或宏中轻松表达的模式。例如,库函数可能总是返回一个int,它总是表示同一组非零错误。编写一个调用不安全代码并将返回结果强制转换为Result<()、LibraryError>的私有宏可以节省大量样板文件。注意这些构造,通过一点重构,您可以节省自己几个小时的工作。
我不会撒谎的。正确地做这件事需要做很多工作。但是正确的操作会产生无bug的代码。如果您的C库是实心的,并且包装层是正确的,那么您将不会看到一个分段错误或缓冲区溢出。您将立即看到任何错误。当你在应用程序代码中犯了以前的指针错误时,它根本不会编译;当应用程序代码编译时,它只会工作。
原文:https://medium.com/dwelo-r-d/wrapping-unsafe-c-libraries-in-rust-d75aeb283c65
本文:http://jiagoushi.pro/node/1451
讨论:请加入知识星球【全栈和低代码开发】或者微信【it_training】或者QQ群【11107767】
- 47 次浏览
【编程语言】Rust 1.50到Rust 1.58.1的新增功能
与 C、C++、Go 和您可能使用的其他语言相比,Rust 编程语言的独特方法可以生成更好的代码,并且妥协更少。 它还会定期更新,通常是每月更新一次。
在哪里下载最新的 Rust 版本
如果您已经通过 rustup 安装了以前版本的 Rust,您可以通过以下命令访问最新版本:
$ rustup update stable
Rust 1.58.1 中的新功能
该版本于 2022 年 1 月 20 日发布,就在 Rust 1.58 之后的几天,修复了 std::fs::remove_dir_all 标准库函数中的竞争条件。此漏洞在 CVE-2022-21658 中进行了跟踪,并发布了公告。攻击者可以利用此安全问题诱使特权程序删除攻击者无法访问或删除的文件和目录。 Rust 1.0 到 1.58 版本受此漏洞影响。建议用户更新他们的工具链并使用更新的编译器构建程序。
Rust 1.58.1 还解决了 Rust 1.58 中引入的诊断和工具中的几个回归问题:
- non_send_fields_in_send_ty Clippy lint 被发现误报过多,已被移至名为“nursery”的实验性 lints 组。
- useless_format Clippy lint 已更新以处理格式字符串中捕获的标识符,这是在 Rust 1.58 中引入的。
- 修复了 Rustfmt 中的回归,防止生成的文件在通过标准输入时被格式化。
- rustc 在某些情况下显示的错误消息已得到修复。
Rust 1.58 中的新功能
1 月 13 日宣布的 Rust 1.58 具有以格式字符串捕获的标识符。有了这个功能,格式字符串现在可以通过在字符串中写入 {ident} 来捕获参数。格式早已接受位置参数和命名参数,例如:
println!("Hello, {}!", get_person()); // implicit position
println!("Hello, {0}!", get_person()); // explicit index
println!("Hello, {person}!", person = get_person()); // named
现在,命名参数也可以从周围的范围中捕获。
Rust 1.58 中的另一个新功能:在 Windows 目标上,std::process::Command 将不再在当前目录中搜索可执行文件,这是 win32 CreateProcess API 历史行为的影响。 这修复了在处理不受信任的目录时搜索可能导致意外行为或恶意结果的情况。
Rust 1.58 还在标准库中引入了更多的#[must_use]。 #[must use] 属性可以应用于类型或函数,如果没有明确考虑它们或者它们的输出几乎可以肯定是一个错误。 Rust 1.58 还具有稳定的 API,例如 Metadata::is_symlinkcode 和 Path::is_symlink。
Rust 1.57 中的新功能
12 月 2 日发布的 Rust 1.57 带来了恐慌! (用于终止处于不可恢复状态的程序)到 const 上下文。以前,恐慌!宏在 const fn 和其他编译时上下文中不可用。现在这已经稳定下来。随着 panic! 的稳定化,其他几个标准库现在可以在 const 中使用,例如 assert!。但这种稳定性还不包括完整的格式化基础设施。恐慌!必须使用静态字符串或要与 {} 一起使用的单个插值来调用宏。预计这种支持将在未来扩大。
Rust 1.57 中的其他新功能和改进:
- Cargo 增加了对任意命名配置文件的支持。
- 对于 Vec、String、HashMap、HashSet 和 VecDeque,try_reserve 已经稳定。此 API 使调用者能够错误地为这些类型分配后备存储。
- 其他多个 API 已稳定,包括 [T; N]::as_mut_slice 和 [T; N]::as_slice。
- 宏属性现在可以跟随#derive 并且将看到原始输入。
Rust 1.56 中的新功能
10 月 21 日宣布,Rust 1.56 是支持 Rust 2021 版本的语言的第一个版本。 Rust 2021 版允许 Rust crate 作者选择中断语言更改,使 Rust 更易于使用和更一致。 crates 可以随时选择加入,并保持与旧版本中的 crates 的互操作性。 Rust 编译器支持该语言的所有三个版本:2015、2018 和 2021。
Rust 1.56 中的其他新功能包括:
- 闭包中的不相交捕获,以简化闭包的编写。
- Cargo.toml 现在支持 [package] [rust-version] 字段来指定 crate 支持的最低 Rust 版本,如果不满足,Cargo 将退出并出现早期错误。虽然目前这不会影响依赖解析器,但其目的是在兼容性问题变成隐秘的编译器错误之前捕获它们。
- 支持 binding@pattern 中的新绑定。 Rust 模式匹配可以使用绑定整个值的单个标识符编写,然后是 @ 和更完善的结构模式,但直到现在才允许在该模式中进行其他绑定。此功能在 Rust 1.0 之前已被允许,但由于不健全而被删除。编译器团队现在已经确定这种模式在稳定的 Rust 中是安全且允许的。
- 恐慌宏现在总是需要格式字符串,就像 printlin!()。
- 许多 API 已经稳定,包括 std::os::unix::fs::chroot 和 UnsafeCell::raw_get。
Rust 1.55 中的新功能
2021 年 9 月 9 日宣布,Rust 1.55 提供更快、更正确的浮点解析。浮点解析的标准库实现已更新为使用 Eisel-Lemire 算法,这带来了速度和正确性的改进。以前,某些边缘情况无法解析,但现在已修复。
同样在 Rust 1.55 中:
- 模式中开放范围的使用已经稳定。
- 许多方法和特征实现已经稳定,包括 Bound::cloned 和 Drain::as_str。
- Cargo 现在对编译器错误进行重复数据删除,并在编译结束时打印报告。以前,当运行 cargo test、cargo check ---所有目标或在多个配置中构建相同 Rust crate 的类似命令时,错误和警告可能会重复出现,因为 rustc 执行并行运行并显示相同的警告。
Rust 1.54 中的新功能
7 月 29 日发布,Rust 1.54 支持在属性中调用类似函数的宏。类函数宏可以是基于宏规则的宏!或者它们可以是过程宏,像宏一样调用!(…)。一个值得注意的用例是将其他文件中的文档包含到 Rust 文档注释中。
Rust 1.54 中的其他新特性:
- wasm32 平台的一些内在函数已经稳定。这些可以访问 WebAssembly 中的 SIMD 指令。
- 默认情况下重新启用增量编译。它在 Rust 1.52.1 中默认被禁用。在 Rust 1.52 中,在从磁盘缓存加载增量编译时添加了额外的验证,导致在验证将这些静默错误变为内部编译器错误 (ICE) 时发现了预先存在的潜在健全性问题。从那时起,已经完成了解决这些问题的工作,一些修复在 Rust 1.53 中登陆,大多数修复在 Rust 1.54 中。可能导致 ICE 的剩余问题在实践中被认为是罕见的。
- 多种方法和特征实现已经稳定。
- 编译器输出已针对调试 C++ 的 Windows MSVC 平台上的枚举进行了改进。
Rust 1.54 紧随 6 月 17 日发布的 Rust 1.53,其中包含语言和库功能,包括数组的 IntoIterator 实现。
Rust 1.52 中的新功能
在 5 月 6 日推出的 Rust 1.52 是通过对 Clippy 工具支持的增强来领导的,Clippy 是用于查找错误和改进 Rust 代码的 lint 集合。以前,运行 cargo check 后跟 cargo clippy 实际上不会运行 Clippy,Cargo 中的构建缓存不会区分两者。这已在 Rust 1.52 中修复。同样在 1.52 版本中,稳定了以下方法:
Arguments::as_strchar::MAXchar::REPLACEMENT_CHARACTERchar::UNICODE_VERSIONchar::decode_utf16char::from_digitchar::from_u32_uncheckedchar::from_u32slice::partition_pointstr::rsplit_oncestr::split_once
几个以前稳定的 API,包括 char::len_utf8 和 u8LLeq_ignore_ascii_case,现在都是 const。 对于编译器,默认 LLVM 已升级到 LLVM 12。该语言的后续版本 Rust 1.52.1 于 5 月 10 日发布,为增量编译中的错误提供了一种解决方法,该错误在 Rust 1.52 中成为编译器错误 .0. Rust 构建者建议升级到 1.52.1 或禁用增量编译。
Rust 1.51.0 中的新功能
发布于 2021 年 3 月 25 日,Rust 1.51.0 版本是相当长一段时间以来对语言和 Cargo 包管理器的最大补充之一,它稳定了 const 泛型的 MVP(最小可行产品)实现和新的功能解析器 货运是亮点之一。 其他亮点:
-
使用 const generics MVP,为库设计者添加了一个用于开发编译时安全 API 的工具。一个备受期待的特性,const 泛型是泛型参数,其范围是常量值,而不是类型或生命周期。例如,这允许类型通过整数参数化。计划是逐步引入 const 泛型,因此目前唯一可以用作 const 泛型参数的类型是整数类型,包括 size、usize、char 和 bool。 -
除了 const 泛型,还稳定了一个使用它的新 API,std::array::IntoIter,它允许开发人员在任何数组上创建按值迭代器。 -
对于 Cargo,新的特征解析器引入了一种用于计算包特征的算法,以帮助避免与当前解析器的一些不必要的统一。 -
改进了 MacOS 上的编译时间,改进了包含调试信息的构建速度并减少了使用的磁盘空间量。 -
除了类型和生命周期之外,函数、特征和结构等项目还可以通过常量值进行参数化。 -
稳定的 API,包括稳定切片和 Peekable 等类型的 18 种新方法。
Rust 1.50.0 中的新功能
发布于 2021 年 2 月 11 日,Rust 1.50.0 改进了数组索引,扩展了对联合字段的安全访问,并添加到标准库中。具体改进包括:
-
对于 const 泛型数组索引,此版本继续向稳定的 const 泛型发展,为数组添加 ops::Index 和 IndexMut 的实现 [T; N] 对于任何长度的 Const N。索引运算符 [ ] 已经通过编译器对数组起作用,但在类型级别,数组直到现在才真正实现库特征。此外,正式承认在数组重复中稳定使用 const 值。 -
允许对 ManuallyDrop<T> 联合字段进行安全分配。 -
现在允许在 Unix 平台上使用 File。有了这个特性,Rust 中的某些类型对什么是有效值有限制,这可能无法涵盖可能的内存值范围。任何剩余的有效值都称为利基,该空间可用于类型布局优化。在 Unix 平台上,Rust 的 File 由系统的文件整数描述符组成;这恰好有一个可能的利基,因为它不能是-1!返回文件描述符的系统调用使用 -1 来指示发生了错误,因此 -1 永远不可能是真正的文件描述符。从 Rust 1.50 开始,它被添加到类型定义中,因此它也可以用于布局优化。因此,Option<File> 现在将具有与 File 相同的大小。 -
对于 Cargo,添加了一个 [rustc-workspace-wrapper] 选项,以设置一个包装器来执行而不是 rustc,仅适用于工作区成员。此外,在 cargo update 命令中添加了 --workspace 标志。 -
库中添加了九个新的稳定函数:bool::then、btree_map::Entry::or_insert_with_key、f32::clamp、f64::clamp、hash_map::Entry::or_insert_with_key、Ord::clamp、RefCell::take 、 slice::fill 和 UnsafeCell::get_mut。 -
同样在库中,几个现有函数被设为 const:IpAddr::is_ipv4、IpAddr::is_ipv6、Layout::size、Layout::align、Layout::from_size_align、pow 用于所有整数类型、checked_pow 用于所有整数类型、saturating_pow对于所有整数类型,wrapping_pow 对于所有整数类型,next_power_of_two 对于所有无符号整数类型,checked_power_of_two 对于所有无符号整数类型。
原文:https://www.infoworld.com/article/3267624/whats-new-in-the-rust-language.html
本文:https://jiagoushi.pro/node/1811
- 32 次浏览