category

Snowflake Cortex中的大型语言模型由Snowflak托管和完全管理,您无需进行任何事先设置。现在,您已经将模型托管在离数据所在位置更近的位置,它为您提供了企业所需的性能、可扩展性和治理。
Snowflake Cortex让您可以即时访问由Mistral、Meta和谷歌等公司的研究人员培训的行业领先的大型语言模型(LLM)。
执行摘要:
- 可用功能
- 了解成本
- 限制
可用功能
Snowflake Cortex功能以SQL函数的形式提供,也可在Python中使用。可用功能概述如下。
CORTEX.COMPLETE():
如果出现提示,COMPLETE函数后面的说明将使用您选择的语言模型生成响应。在最简单的用例中,提示是一个字符串。您还可以提供一个对话,包括多个提示和响应,用于交互式聊天风格的使用,在这种形式的功能中,您还可以指定超参数选项来自定义输出的风格和大小。
欲了解完整指南,请查看以下文章:
CORTEX.EXTRACT_ANSWER():
该函数从文本文档中提取给定问题的答案。该文档可以是纯英文文档,也可以是半结构化(JSON)数据对象的字符串表示。
欲了解完整指南,请查看以下文章:
CORTEX.SENTIMENT():
此函数返回给定英语输入文本的情感得分。
欲了解完整指南,请查看以下文章:
CORTEX.TRANSLATE():
This function translates the given input text from one supported language to another.
For Full Guide, check out below article:
Understanding Cost
Snowflake Cortex LLM functions incur compute cost based on the number of tokens processed. The table below shows the cost in credits per 1 million tokens for each function.
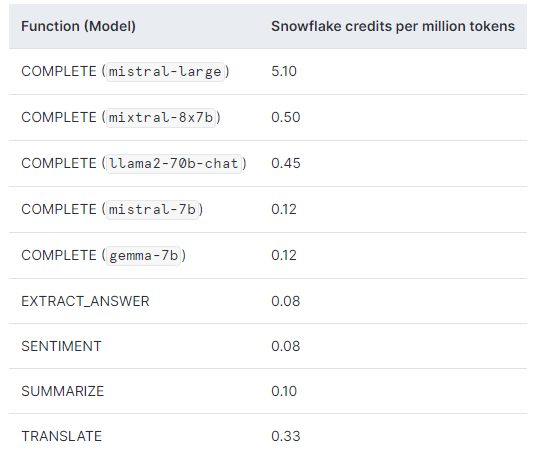
A token is the smallest unit of text processed by Snowflake Cortex LLM functions, approximately equal to four characters of text.
- For functions that generate new text in the response (COMPLETE, SUMMARIZE, and TRANSLATE), both input and output tokens are counted.
- For functions that only extract information from the input (EXTRACT_ANSWER and SENTIMENT), only input tokens are counted.
- For EXTRACT_ANSWER, the number of billable tokens is the sum of the number of tokens in the
from_textandquestionfields.
Restrictions
Models used by Snowflake Cortex have limitations on size as described in the table below. Sizes are given in tokens. Tokens generally correspond to words, but not all tokens are words, so the number of words corresponding to a limit is slightly less than the number of tokens. Inputs that exceed the limit result in an error.
Documentation Link:
https://docs.snowflake.com/en/user-guide/snowflake-cortex/llm-functions
- 登录 发表评论
- 11 次浏览